Accueil GLiNER : le succès du modèle de reconnaissance d’entités nommées par F.initiatives
Le modèle GLiNER par F.initiatives
GLiNER : le succès du modèle de reconnaissance d'entités nommées par F.initiatives
F.initiatives, via son lab en France spécialisé en IA, a créé le modèle GLiNER de reconnaissance d’entités nommées. Ce modèle d’Intelligence Artificielle (IA) connait un grand succès au sein de la communauté scientifique.
On vous explique tout dans cet article !
Reconnaissance d'entités nommées ou Named Entity Recognition (NER) en anglais : c'est quoi ?
La reconnaissance d’entités nommées, ou Named Entity Recognition (NER) en anglais, est une méthode de traitement automatique du langage naturel (TALN) et sous-catégorie de l’intelligence artificielle (IA) et du machine learning (ML).
Named Entity Recognition : extraction d'information dans un texte brut
Sous-tâche de l’extraction d’informations dans des corpus documentaires, le NER vise à identifier et classifier des entités nommées dans un texte brut non structuré, en catégories prédéfinies, telles que noms de personnes, noms d’entreprises, dates, lieux, codes médicaux, quantités, valeurs monétaires, et bien d’autres…
GLiNER: Generalist Model for Named Entity Recognition
GLiNER (Generalist Model for Named Entity Recognition) est un modèle de reconnaissance d’entités nommées (NER) développé en interne chez F.initiatives, par notre pôle R&D en collaboration avec le LIPN (Laboratoire Informatique de Paris Nord).

Urchade Zaratiana, Research Scientist, a eu l’occasion de présenter l’article scientifique durant la conférence NAACL24.
La conférence NAACL24 (Annual Conference of the North American Chapter of the Association for Computational Linguistics) a eu lieu du 16 au 21 juin 2024, dans la ville de Mexico, au Mexique.
Comment fonctionne le modèle GLiNER ?
GLiNER est un modèle utilisant un encodeur transformateur bidirectionnel (de type BERT) pour l’extraction d’entités ouvertes. Il est capable d’identifier n’importe quel type d’entité dans un texte.
Contrairement aux modèles NER traditionnels, qui sont limités à des entités prédéfinies, et aux grands modèles linguistiques (LLM) qui sont coûteux et volumineux pour les scénarios à ressources limitées, le modèle GLiNER offre une alternative innovante.
Son fonctionnement est simple : il suffit d’épeler la catégorie d’entité que l’on veut détecter, et GLiNER trouvera des entités dans le texte brut non structuré !
Différents versions de GLiNER
Le modèle GLiNER possède plusieurs versions, y compris des versions générales et des versions fine-tunées pour des applications spécifiques.
- La version fine-tunée urchade/gliner_multi_pii-v1 est capable de reconnaître divers types d’informations personnelles indentifiables (IPI) tels que les noms, numéros de téléphone, adresses, numéros de passeport, courriels, et bien plus encore.
- La version urchade/gliner_large_bio-v0.1 est adaptée pour reconnaître divers types d’entités dans le domaine biomédical.
- Le modèle wjbmattingly/gliner-large-v2.1-bird est spécialisé dans la reconnaissance des attributs des oiseaux.
- La version GLiNER news est conçue pour identifier et classer les entités spécifiques dans les articles d’actualité.
- GLiNER possède également des versions spécialisées pour des langues spécifiques telles que l’italien ou le coréen, ainsi qu’une version multilingue capable de traiter des textes dans plusieurs langues.
Exemple d'utilisation
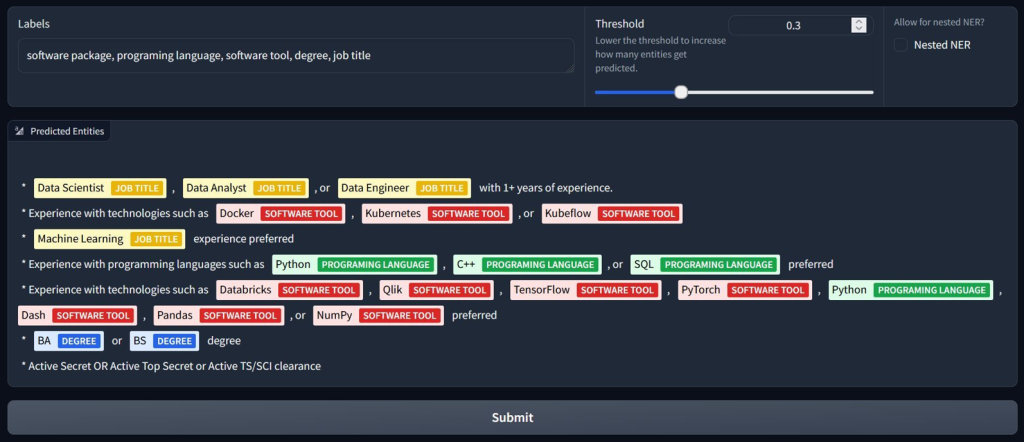
Dans cet exemple, le modèle GLiNER a réussi à identifier et classifier les entités nommées dans un texte brut, en fonction des étiquettes demandées par l’utilisateur, à savoir l’intitulé de poste, l’outil logiciel, le langage de programmation et le diplôme.
Pour découvrir d’autres exemples d’utilisation, direction le GitHub GLiNER !
Les points forts du modèle GLiNER
Utilisation simplifiée via Python
Nos équipes ont développé un module pratique qui peut être installé à l’aide de pip. Le modèle est ainsi directement utilisable et ne requiert pas d’entrainement.
L’utilisation du modèle GLiNER se fait en seulement 3 lignes de code : import, load, run. Il suffit de spécifier dans une liste Python les entités que l’on veut extraire d’un texte. Cette liste est modifiable à volonté : il faut simplement de la modifier et relancer le modèle pour obtenir d’autres entités.
Quiconque a déjà travaillé sur des problèmes de NER sait à quel point il est fastidieux et coûteux de collecter des étiquettes pour entraîner ces modèles. Par conséquent, le modèle GLiNER, avec son fonctionnement zero-shot, est près de 90 fois moins grands que les autres modèles zero-shot existants utilisant des grands modèles de langues, offrant un énorme gain de temps et en ressource de calcul ! En effet, le modèle GLiNER dispose d’une inférence très efficace et se distingue des autres modèles existants puisqu’il peut fonctionner sur unité centrale (CPU).
Surpasse les autres modèles grâce au zero-shot learning
Les points forts du modèle GLiNER
C’est grâce à tous ces points forts et la grande avancée qu’il permet dans le domaine du NER, que le modèle GLiNER connait un tel succès !
Reconnu par la communauté scientifique
En effet, le modèle a fait beaucoup de bruit à l’international, avec de nombreux posts LinkedIn au sein de la communauté scientifique, tels que le post de Marie Stephen Leo, Data Director de Sephora, ou bien celui de Tom Aarsen, Machine Learning Engineer chez Hugging Face, quelques articles sur Medium (comme celui-ci) ou encore des vidéos explicatives sur YouTube (comme celle-là).
Nombreux téléchargements
L’ensemble des modèles GLiNER originaux, réalisés par Urchade Zaratiana, ont été téléchargés environ 270 000 fois en mai 2024 sur Hugging Face. De plus, une version fine-tuné de GLiNER (modèle ré-entrainé sur d’autres données) a elle été téléchargée près de 2 millions fois sur Hugging Face.
La librairie Python GLiNER a été installée environ 87 000 fois ! Cette librairie est une façon, entres autres, de télécharger et utiliser les différents modèles. Une fois qu’une personne a installé la libraire, elle peut potentiellement télécharger plusieurs modèles.
Réduction de l'émission de CO2
Notre modèle GLiNER est plus de 500 fois moins couteux que GPT4.
Notre Research Lab a réalisé une projection estimative avec le cas réel d’une entreprise qui a annoncé utilisé GLiNER environ 400 000 fois par jour pour annoter automatiquement des textes scrappé sur internet.
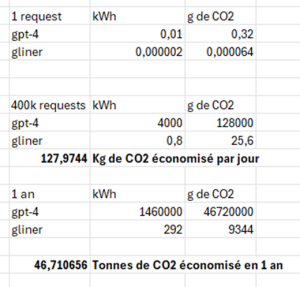
Selon nos estimations, sur 1 an, c’est 46 tonnes de CO2 économisés, juste pour cette entreprise !