Accueil SemEval 2024 : F.initiatives décroche la 2ème place du classement
SemEval-2024,
notre participation
SemEval 2024 : F.initiatives décroche la deuxième place du classement
F.initiatives, via son Research Lab spécialisé en Intelligence Artificielle (IA), a participé au concours international SemEval-2024 sur la Task 8 : « Multigenerator, multidomain, and multilingual black-box machine-generated text detection« . Le modèle développé en interne a obtenu la deuxième place (sur 338 participants) sur la sous-tâche de détection de texte multilingue généré par IA !
On vous explique tout dans cet article !
Le concours international SemEval : c'est quoi ?
Le concours international SemEval (Semantic Evaluation), une référence majeure du domainae, consiste en une série de workshops de recherche en traitement automatique du langage naturel (TALN) ayant comme objectif l’amélioration de l’analyse sémantique et la création des ensembles de données annotées pour des problèmes sémantiques complexes.
Pour la 18ème édition de SemEval en 2024, 10 tâches (Tasks) avaient été proposées dans le cadre de 4 principaux axes de recherche en analyse sémantique : Relations Sémantiques, Discours et Argumentation, Capacités des Modèles de Langage à Grande Échelle (LLM), Représentation de la Connaissance et Raisonnement. F.initiatives a participé à la Task 8 de cette édition, concernant la sous-tâche de détection de texte multilingue généré par des machines.
Task 8 : Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Les LLMs (Large Language Model), comme GPT, ont ouvert la voie à l’évolution et l’adoption généralisée des modèles de génération de texte, qui ont considérablement influencé le paysage de la communication numérique et de la création de contenu. Si ces avancées sont synonymes d’une nouvelle ère d’efficacité et de créativité, permettant des applications allant d’aides à l’écriture sophistiquées à des agents conversationnels avancés, elles viennent également avec d’importants défis et des questions éthiques.
La prolifération des textes générés par l’IA a suscité des inquiétudes quant à la diffusion de fausses informations, au renforcement de la fraude académique et à l’érosion potentielle de la confiance dans les contenus numériques. Il est donc urgent de trouver des solutions solides pour identifier les contenus générés par l’IA, afin de préserver l’intégrité de l’information tout en profitant des avancées de l’IA.
Ce défi est remarquable par sa complexité, car elle implique de classifier des textes générés par plusieurs modèles, provenant de différents domaines et écrits dans plusieurs langues. Pour réussir à détecter un texte généré par une IA, un modèle doit être capable de généraliser efficacement dans différents contextes et langues.
Le modèle F.initiatives
Les membres du Research Lab de F.initiatives, Maha Ben Fares, Research Scientist, Simon Hernandez, Research Scientist, Urchade Zaratiana, Research Scientist et Pierre Holat, Responsable de la Recherche, ont développé en interne un modèle répondant à la détection de texte multilingue généré par une IA.
Dans leur article scientifique (disponible ici) ils ont présenté leur proposition de système qui a pour objectif de classifier si un texte a été généré par de l’IA ou un humain. Pour relever ce défi, notre Research Lab a proposé une architecture syntaxiquement motivée. Notre approche s’inspire principalement du fait que les textes générés par les IA et les humains sont sémantiquement similaires, puisqu’ils sont dérivés de distributions topiques comparables. Par conséquent, nous soutenons que la distinction entre eux réside dans leur syntaxe et leur style d’écriture.
En règle générale, la classification de textes basée sur l’architecture de réseau de neurones profond de types « transformers » s’appuie sur les informations de la dernière couche pour la classification. Cependant, notre modèle adopte une approche différente en agrégeant dynamiquement et de manière sélective des informations provenant de toutes les couches du « transformer» pour évaluer individuellement les jetons, étant donné que chaque couche peut contenir des informations distinctes.
Des études antérieures (Peters et al., 2018; Jawahar et al., 2019; Tenney et al. 2019) révèlent une distribution inégale des caractéristiques linguistiques dans l’architecture du transformateur : les détails syntaxiques étant principalement présents dans les couches initiales et les informations sémantiques complexes dans les couches plus profondes.
En utilisant des informations provenant de toutes les couches, notre modèle vise à capturer l’ensemble des indices linguistiques, améliorant ainsi sa capacité à différencier avec précision le contenu généré par l’homme de celui généré par l’IA. Reposant sur une stratégie de fusion hiérarchique des représentations des couches du « transformer», notre modèle met l’accent sur les informations syntaxiques plutôt que sémantiques. Cette approche permet ainsi de capturer des structures phrastiques plus complexes, ce qui aide à distinguer plus efficacement le style et la syntaxe d’un texte.
Notre modèle va au-delà de la pratique standard qui consiste à utiliser uniquement le jeton [CLS] pour la classification dans les classificateurs basés sur BERT. Il applique l’étiquetage des séquences pour classer chaque élément du texte comme étant humain ou artificiel. Cette approche traite la classification binaire des textes comme une prédiction au niveau des jetons, la classification finale étant la moyenne des prédictions des jetons.
Notre système appliqué en interne
Nous sommes même allés plus loin que cela, puisque nous avons intégré les résultats de ces travaux dans Chat With Documents. Il s’agit d’une fonctionnalité qui vient enrichir notre intelligence artificielle, SoFIA, 100 % développée en interne. Elle permet de charger plusieurs documents de tout type (Word, PowerPoint, PDF, e-mail, image, Excel, etc.) dans une session de chat avec SoFIA. Cette fonctionnalité permet d’accélérer considérablement la lecture, la compréhension et l’extraction de données essentielles de la documentation projet.
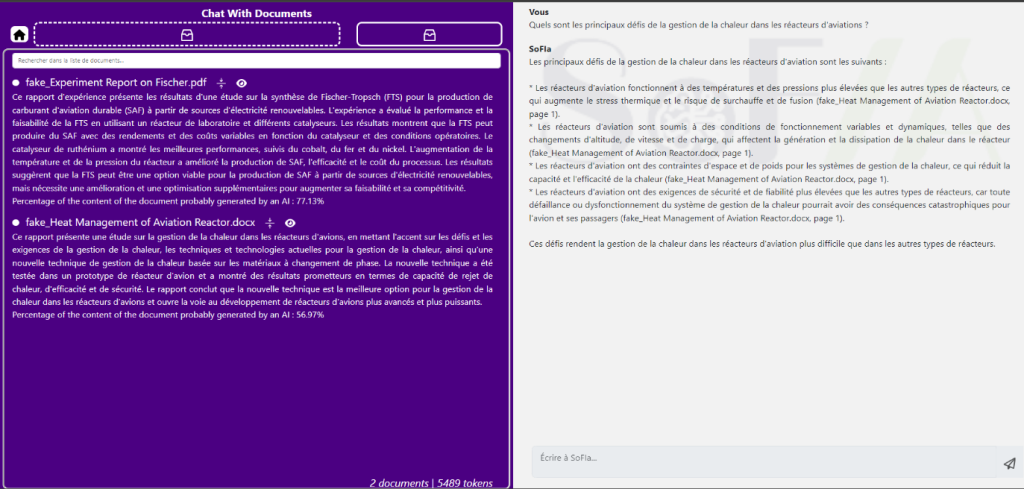
Le principe est simple :
- Les documents clients sont téléchargés sur notre plateforme interne 100 % sécurisée.
- L’IA analyse le contenu et propose un résumé des informations essentielles contenues dans ces documents, tout en indiquant le pourcentage estimé de contenu qui pourrait avoir été généré par une IA.
- L’utilisateur pose n’importe quelle question à l’IA, qui ne répondra qu’à partir des informations contenues dans les documents.
Il est important de repréciser que nos modèles d’IA générative sont entièrement On-Premise, aucune donnée ne sort des locaux de F.initiatives à Puteaux.
L’intégration du modèle développé dans le cadre de nos travaux pour le concours international SemEval-2024, nous permet ainsi de déterminer si un document client a été majoritairement généré par une IA. Cette fonctionnalité améliore significativement la conformité de nos dossiers clients, renforçant ainsi notre compliance.

L’intégration du modèle développé dans le cadre de nos travaux pour le concours international SemEval-2024, nous permet ainsi de déterminer si un document client a été majoritairement généré par une IA. Cette fonctionnalité améliore significativement la conformité de nos dossiers clients, renforçant ainsi notre compliance.
Le succès de notre participation à SemEval 2024
Notre classement
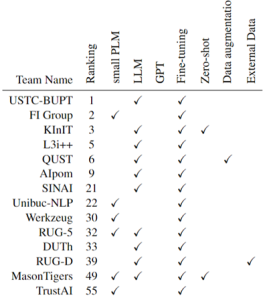
F.initiatives a connu un net succès au concours international SemEval-2024 puisque notre modèle démontre une performance compétitive sur l’ensemble de données de test, atteignant une précision de 95,8 %. Nous permettant ainsi d’obtenir la deuxième place dans la sous-tâche A multilingue, avec seulement 0,1 % de retard sur le système leader.
Il convient de souligner que notre modèle a obtenu des performances robustes dans divers domaines et langues inédits, démontrant son adaptabilité et sa capacité de généralisation. Notamment si l’on considère que nous avons utilisé un modèle plus petit que les autres systèmes proposés qui s’appuient souvent sur des LLMs finetunés. En effet, notre modèle est significativement plus petit, et par conséquent nettement moins onéreux et énergivore, que ceux utilisés par tous nos concurrents classés jusqu’à la 22ème position.
NAACL 2024, un autre succès F.initiatives
La conférence NAACL24 (Annual Conference of the North American Chapter of the Association for Computational Linguistics) a lieu du 16 au 21 juin 2024, dans la ville de Mexico, au Mexique.

Lors de cette conférence NAACL24, Simon Hernandez a eu l’opportunité de présenter notre participation au concours international SemEval-2024. Cette même conférence a également été l’occasion pour notre Research Lab de présenter son article scientifique concernant le modèle GLiNER, aussi développé en interne chez F.initiatives.
Vous voulez en savoir plus ? Consultez notre article sur le modèle GLiNER !